Java Magazin 12.2018 - Event Storming

Erhältlich ab: November 2018
Autoren / Autorinnen:
Marco Schulz ,
Wolf-Dieter Roth ,
Konstantin Diener ,
Arne Limburg ,
,
Johannes Dienst ,
Manfred Steyer ,
Sebastian Meyen ,
Martin Maier ,
Henning SchwentnerStefan Hofer ,
Falk Sippach ,
Manuel Mauky ,
Elena BochkorDr. Veikko Krypczyk ,
Henning SchwentnerMarco Heimeshoff ,
Pierre Gronau ,
Tam Hanna
Damit einmal getroffene Entscheidungen auf lange Sicht keine Dramen verursachen, sind einige Spielregeln zu beachten. Ganz besonders gilt das für den Entwurf eines API, das naturgemäß über einen langen Zeitraum Verwendung findet.
Die Motivation, für eine eigene Anwendung und vor allem für Programmbibliotheken eine definierte Schnittstelle bereitzustellen, die die Interaktion mit anderen Programmen ermöglicht, ist in vielen Projekten sehr hoch. Doch nicht immer gelingt dieses Vorhaben. Deutlichste Anzeichen für ein verunglücktes API sind häufige Änderungen, die mit Vorgängerversionen inkompatibel sind. Die damit verbundenen Probleme kennt jeder, der einmal innerhalb eines Projekts eine vorhandene Bibliothek gegen eine neuere Version austauschen musste. Je nach Intensität der Nutzung erfordert ein Update kleinere oder sogar sehr große Codeanpassungen.
Aber auch bei korrekter Durchführung ist die bei Verwendung eines API erwartete Flexibilität nicht immer gewährleistet. Theoretisch ist es bei einem korrekten Entwurf möglich, die Implementierung zu einem API problemlos auszutauschen. In realen Projekten tritt dieser Idealfall eher selten ein. Die Ursache ist recht trivial: Solange die Hersteller einer Implementierung dem vom API definierten Standard komplett folgen, ist alles optimal. Ein Beispiel für einen solchen Standard ist die Java Database Connectivity (JDBC). Viele Datenbankhersteller, die für ihr DBMS die JDBC implementieren, haben jedoch mit Schwierigkeiten zu kämpfen. Denn die Systeme unterscheiden sich in einigen Details. So kennt MySQL zum Erzeugen des Primärschlüssels Auto Increment – eine Funktion, die bei Enterprise-Lösungen fehlt. Solche Feinheiten haben zur Folge, dass viele Contributors den Standard nicht komplett implementieren. Ebenso sind Erweiterungen außerhalb der festgelegten Definition häufig. Deshalb sollte klar sein, dass ein einen Standard definierendes API einen Kompromiss aus minimalen Anforderungen darstellt. So lässt sich sehr leicht einsehen, welche Komplikationen sich bei einem Austausch der Implementierungen ergeben können.
Die Verarbeitung von XML zeigt einen anderen Aspekt auf. Es existieren die Standards DOM, SAX und StAX. Entscheidet man sich bei der Implementierung ursprünglich für DOM und steigt aus Gründen der Performanceverbesserung auf SAX um, stellt man schnell fest: Beide Implementierungen und APIs sind weitgehend inkompatibel. Das Problem lässt sich anhand des Beispiels PDF-Verarbeitung konkretisieren. Obwohl es sich bei PDF um einen Standard handelt, existiert für Programmbibliotheken keine allgemein definierte Schnittstelle. Entsprechend präsentiert sich der Datentyp PdfReader in der iText-Bibliothek [1]. Dieser definiert für das eigene API den Rückgabewert der Methode, um PDF-Dokumente einzulesen. Zwar wirken die erwähnten Beispiele ein wenig pessimistisch, jedoch zeichnen sie ein deutliches Bild von den Grenzen der Flexibilität.
Semantic Versioning
Noch vor dem ersten Entwurf gilt es, sich mit der Versionsnummernvergabe zu beschäftigen. Das bewährte Semantic Versioning [2] legt klar fest, wie die einzelnen Bereiche einer Version inkrementiert werden sollen (Abb. 1).
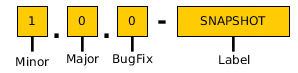 Abb. 1: Semantic Versioning
Abb. 1: Semantic VersioningMajor: Rückwärts inkompatibel. Das trifft zu, sobald eine Klasse oder Methode geändert oder gelöscht wurde. Diese Veränderungen erfordern Codeanpassungen.
Minor: Erweiterungen. Sämtliche vorhandenen Methoden und deren Signaturen bleiben unverändert. Es werden lediglich weitere Methoden hinzugefügt.
Bugfix: Ausschließlich Fehlerkorrekturen. Es werden keine zusätzlichen Funktionen mit eingebracht.
Die Einhaltung dieser Konvention ermöglicht vorhandenen Konsumenten des API eine bessere Risikoabschätzung. Anhand der Release Notes lässt sich erkennen, ob das eigene Projekt von der Inkompatibilität betroffen ist. Auch vermittelt die Häufigkeit veröffentlichter Major Releases einen Eindruck von der Stabilität des Projekts.
Scheibchenweise
Die Verwendung des Semantic Versionings regelt in groben Umrissen bereits den Releaseprozess. Der nächste Schritt zum Entwurf einer gemeinsamen Programmierschnittstelle führt zur Architektur. Eine moderne Adaption des klassischen MVC-Entwurfsmusters ist die Schichtenarchitektur. Auch dieser Ansatz trennt Verantwortlichkeiten von Datenhaltung, Repräsentation und Geschäftslogik. Er geht allerdings noch einen Schritt weiter: Die definierten Schichten bauen aufeinander auf und können nur von darüberliegenden Schichten angesprochen werden. Dieses Prinzip ist bereits aus dem OSI-Referenzmodell [3] bekannt. Wie ein solches Schichtenmodell für Applikationen aussehen kann, zeigt Abbildung 2.
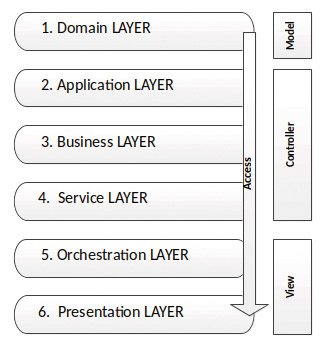 Abb. 2: Schichtenmodell für Applikationen
Abb. 2: Schichtenmodell für ApplikationenEs sei erwähnt, dass auf GitHub [4] ein Beispielprojekt zu finden ist, das die hier besprochenen Punkte umsetzt. Der Domainlayer auf Ebene 1 hält die Datenobjekte bereit. Auf Ebene 2 enthält die vorgeschlagene Architektur die Implementierungsklassen, während sich auf Ebene 3 die zugehörigen Interfaces befinden. Das führt zum allgemein bekannten Lehrsatz, man solle nicht gegen Interfaces implementieren. Auch wenn das nahezu jeder Programmierer im Schlaf herunterbeten kann, finden sich im beruflichen Alltag nicht wenige Kollegen, denen die Umsetzung des Grundsatzes nicht vollständig bewusst ist. Und das, obwohl sie ihn intuitiv bereits vielfach anwenden. List<Entry> collection = new ArrayList(); ist ein solcher Klassiker, in dem das Interface List durch die ArrayList implementiert ist. Diese Tatsache mag trivial erscheinen. Jedoch existieren genügend Beispiele aus persönlicher Erfahrung, die gezeigt haben, dass eine kurze Erläuterung oft notwendig ist. Bezogen auf Abbildung 2 bedeutet dieses kurze Beispiel, dass das Interface List im Layer 3 und die Klasse ArrayList im Layer 2 aufzufinden sind. Aus dieser Vereinbarung ergibt sich der nächste Punkt, die Namensgebung.
Es ist inzwischen in vielen Projekten üblich, Interfaces mit einem vorangestellten oder angefügten I kenntlich zu machen. Diese Praxis ist jedoch nicht unbedingt empfehlenswert, da sie die Semantik des Sourcecodes nicht verbessert, sondern die Lesbarkeit des Texts erschwert. Als Bezeichnung für Implementierungsklassen hat sich der Suffix Impl bewährt. Dennoch geht unser Beispiel aus dem Java API mit gutem Grund einen anderen Weg: Der Name kennzeichnet hier explizit, dass es sich bei der Implementierung der Liste um eine Arrayliste handelt, nicht um einen Vektor oder ähnliches. Zwar ist dieses Vorgehen sehr ratsam, dennoch gibt es Ausnahmen, bei denen man Implementierungsklassen besser mit dem erwähnten Impl-Suffix benennt. Erinnern wir uns an das Beispiel für XML: Wird eine Toolklasse implementiert, die verschiedene Standards vermischt, ist es schwer, eine exakte Bezeichnung zu finden. Deshalb ist es nicht verkehrt, bereits zu Beginn darauf zu achten, dass die Übersicht erhalten bleibt. Hat man sich einmal auf eine Methodik festgelegt, sollte man diese konsequent beibehalten. Das Aufsplitten von Klassen in verschiedene Funktionalitäten birgt die Gefahr, eine große Ansammlung von Klassen zu generieren, die schwer zu handhaben ist. Das Gleiche gilt für Verzeichnisstrukturen: Weniger ist oft mehr.
Servicewüste?
Die vierte Schicht ist für atomare Services reserviert. Als Beispiel hierfür kann die Implementierung eines einfache E-Mail-Clients dienen. Im Application-Layer sind bereits die Funktionalitäten realisiert, die notwendig sind, um Mails zu erzeugen. So zum Beispiel die Funktionalitäten, Empfänger hinzu- oder Attachments anzufügen. Um diesem Gebilde Leben einzuhauchen, ist eine Instanz nötig, die den tatsächlichen Versand der E-Mails durchführt. Auch die Änderung der Konfiguration wird in einen gemeinsamen Mail-Client-Service ausgelagert. Ebenso wie es sich beim Business-Layer um ein API handelt, stellen diese Services eins dar. Der wichtigste Unterschied bei Services ist, dass aufgrund des fehlenden Mehrwerts und des großen Verwaltungsaufwands auf die Bereitstellung von Interfaces verzichtet wird.
Ebenso verhält es sich mit dem Orchestrationslayer, der für Service-Kompositionen vorgehalten wird. Die in den Schichten 4 und 5 bereitgestellten Klassen können im Sinne einer Service-getriebenen Architektur auch RESTful sein. Die Zuordnung des Orchestrationslayers zur View wird besonders bei Webanwendungen ersichtlich. Entscheidet man sich z B. für JSF als Präsentationsschicht, werden Managed Beans benötigt. Diese kombinieren häufig atomare Services und binden sie ans GUI. Da diese Schicht eher eine statische Durchleitung zu Funktionalitäten darstellt, als den Charakter einer dynamischen Steuereinheit aufzuweisen, ist sie eher der View zuzuordnen.
Um ein stabiles API bereitstellen zu können, ist es notwendig, es auf seine Benutzbarkeit hin zu untersuchen. Dabei helfen aufwendige Analysen weniger als einfaches Ausprobieren. In diesem Zusammenhang sei darauf hingewiesen, dass testgetriebene Entwicklung bereits während der Umsetzungsphase eines Projekts wertvolle Informationen liefern kann.
Testfalle
Das Thema Tests füllt bereits diverse Bücher und wäre einen eigenen Artikel wert. Aber auch bei der Gestaltung eines API spielt die Qualität der Testfälle eine wichtige Rolle. Aus langjähriger Erfahrung entwickeln die meisten Programmierer ihre Funktionalitäten gegen das als Testoberfläche verwendete Applikations-GUI. Die daraus resultierenden Nachteile wurden bereits vielfach besprochen, weshalb wir uns direkt dem Thema Test-driven Design (TDD) zuwenden.
Kern dieses Designparadigmas ist die Entwicklung von Testfällen, die auf der Anforderungsanalyse aufbauen. Eine dagegen geschriebene Implementierung sorgt dafür, dass die Tests nicht mehr fehlschlagen. Ein zugänglicherer Ansatz, TDD in den eigenen Prozess einzubinden, besteht darin, die vorgegebene Spezifikation zu implementieren und daraus die Testfälle abzuleiten. Im Anschluss wird das Resultat mittels Qualitätswerkzeugen wie Cobertura, FindBugs, Checkstyle und PMD verifiziert. Besonders das Erreichen einer hohen Testabdeckung von mehr als 85 Prozent wirkt sich auf die Qualität eines Artefakts aus. Aus diesem Grund muss die Überprüfung der Test-Coverage kontinuierlich erfolgen. Mit Build-Tools wie Maven kann jeder Entwickler das direkt aus seiner IDE heraus bewerkstelligen und entsprechen agieren. Immer wieder werden durch die Verwendung von Bibliotheken mögliche Optimierungen sicht- und umsetzbar. Auch der Vorgang des Testschreibens fördert direkt umsetzbare Einsichten zur Benutzbarkeit der Implementierung.
Probleme mit dem vorgeschlagenen, abgewandelten Vorgehen für TTD ergeben sich in kollaborativen Teams. Diese müssen möglicherweise zunächst Implementierungsergebnisse abwarten, bevor sie sie im eigenen Projekt verwenden können. Ein Effekt, der sich mittels eines modularen Aufbaus und der Vermeidung von transitiven Abhängigkeiten erheblich abschwächen lässt.
Wachmannschaft
Ist die Implementierung eines Interface durch eine ausreichende Anzahl von Testfällen abgedeckt, stellt dies einen aussagekräftigen Funktionsbeweis des API-Designs dar. Dabei sollten die Ergebnisse der Beweisführung bestmöglich dokumentiert werden. In Form der freien Bibliothek apiguardian existiert eine Möglichkeit, den Sourcecode mit der Annotation @API anzureichern. Diese zeigt den Status eines Attributs, einer Methode oder einer Klasse an. Die unkomplizierte Einbindung ins Projekt lässt sich via Maven mit den folgenden Zeilen durchführen:
<dependency>
<groupId>org.apiguardian</groupId>
<artifactId>apiguardian-api</artifactId>
<version>1.0.0</version>
</dependency>Nach Einbindung der Bibliothek können sämtliche API-Komponenten annotiert werden. Die Annotation @ API kennt die beiden Parameter status und since. since kennzeichnet, ab wann ein Interface oder eine Methode verfügbar ist. Das zeigt, wie hilfreich die Verwendung des Semantic Versionings im praktischen Einsatz ist. Der Parameter status wiederum kennt fünf Zustände:
DEPRECATED: Veraltet, sollte nicht weiterverwendet werden.
EXPERIMENTAL: Kennzeichnet neue Funktionen, auf die der Hersteller gerne Feedback erhalten würde. Mit Vorsicht verwenden, da hier stets Änderungen erfolgen können.
INTERNAL: Nur zur internen Verwendung, kann ohne Vorwarnung entfallen.
STABLE: Rückwärtskompatibles Feature, das für die bestehende Major-Version unverändert bleibt.
MAINTAINED: Sichert die Rückwärtsstabilität auch für das künftige Major-Release zu.
Ein Screenshot (Abb. 3) aus der NetBeans IDE, die die API-Annotation für die Interfacemethode log() eines Loggers einblendet, zeigt die Vorteile, die diese Art von API-Dokumentation bietet.
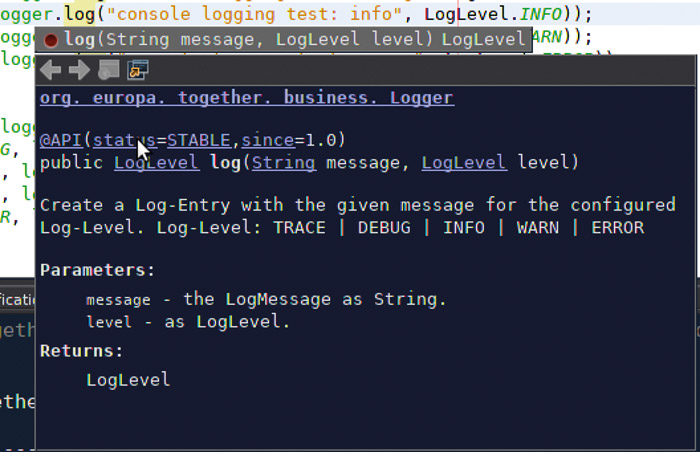 Abb. 3: Vorteile der API-Dokumentation
Abb. 3: Vorteile der API-DokumentationIn Bezug auf die vorgestellte Schichtenarchitektur bedeutet das: Sämtliche Interfaces aus dem Businesslayer und alle Service-Klassen aus dem Service-Layer stellen das API dar und sollten entsprechend annotiert werden.
Zusammenfassung
Das Thema API-Design hält einige nicht zu unterschätzende Tücken bereit. Die Brisanz der Materie hat eine Vielzahl von Checklisten und Anleitungen für API-Entwürfe hervorgebracht. Dieser Beitrag versucht eine Brücke zwischen den Vorgehensmodellen und den Zusammenhängen im Softwareentwurf zu bauen. Denn eins ist gewiss: Nichts ist so beständig wie die Veränderung. Und nicht alle kontinuierlich wiederholten Annahmen in Projektmeetings treffen dadurch ein, dass man sie unermüdlich aufsagt. Qualität und Beständigkeit lassen sich nicht ausschließlich durch den Einsatz von Technologien erreichen, sondern durch die korrekte Verwendung der ausgewählten Werkzeuge und Methoden.
 Marco Schulz studierte an der HS Merseburg Diplominformatik. Seine Schwerpunkte liegen in Softwarearchitekturen, der Automatisierung des Softwareentwicklungsprozesses und dem Softwarekonfigurationsmanagement. Seit über fünfzehn Jahren entwickelt er für namhafte Unternehmen auf unterschiedlichen Plattformen umfangreiche Webapplikationen. Derzeit arbeitet er als freier Consultant und ist Autor verschiedener Fachartikel.
Marco Schulz studierte an der HS Merseburg Diplominformatik. Seine Schwerpunkte liegen in Softwarearchitekturen, der Automatisierung des Softwareentwicklungsprozesses und dem Softwarekonfigurationsmanagement. Seit über fünfzehn Jahren entwickelt er für namhafte Unternehmen auf unterschiedlichen Plattformen umfangreiche Webapplikationen. Derzeit arbeitet er als freier Consultant und ist Autor verschiedener Fachartikel.

Links & Literatur
[1] iText-PDF-Bibliothek https://itextpdf.com
[2] Semantic Versioning: https://semver.org
[3] OSI-Schichtmodell : https://www.elektronik-kompendium.de/sites/kom/0301201.htm
[4] TP-CORE-Beispielanwendung: https://github.com/ElmarDott/TP-CORE/
Einst repräsentierte die Open-Source-Bewegung eine Art Utopia. Fernab hierarchischer Strukturen vernetzten sich Leute, die weit über den Globus verstreut lebten, um sich mit der Entwicklung freier Software zu befassen. Ob bei Linux, Apache, PHP oder Python – es galt stets das Prinzip der Meritokratie, eine Art Leistungskultur, bei welcher demjenigen, der am meisten zum Projekt beiträgt, auch am meisten Entscheidungsbefugnisse zugestanden werden.
Doch wie bei den meisten Revolutionen sind auch bei Open Source die tätigen Revolutionäre selten angenehme Zeitgenossen und die Strukturen, unter welchen kommuniziert wird, alles andere als gerecht. So finden sich analog zur Diktatur des Proletariats der kommunistisch-sozialistischen Bewegungen nicht wenige Hinweise auf die Verherrlichung eines Benevolent Dictators in der Open-Source-Community.
Ein solcher „gütiger Diktator“ ist Linus Torvalds, Erfinder von Linux und seitdem Maintainer des Kernels. Eine von der Informatikprofessorin Megan Squire durchgeführte Analyse ergab, dass in 21 000 E-Mails, die Torvalds innerhalb von vier Jahren an die Linux-Kernel-Mailingliste sendete, etwa eintausend (!) mindestens eines der Wörter „Crap“, „Slut“, „Bitch“, „Bastard“ oder eine Kombination aus diesen enthielt.
Immerhin erkennt der mittlerweile 48-jährige nun an, dass es vielleicht doch eine gute Idee sein könnte, seinem mangelnden Gespür für andere Menschen nicht ungehemmt freien Lauf zu lassen. Torvalds, der noch 2013 die Forderung nach professionellen Umgangsformen barsch zurückwies, entschuldigte sich jetzt in einem Schreiben und will sich vorübergehend von seiner Aufgabe zurückziehen, um an seinem Verhalten zu arbeiten.
Interessant an dem Vorgang ist, dass der rüde Umgangston auf so mancher Open-Source-Mailingliste viele potenzielle, talentierte Mitwirkende abstößt. So werden die Open-Source-Teams einseitig, fernab von jeglicher Idee der Inklusion und Diversität.
Ganz anders übrigens der Gründer und Maintainer der Programmiersprache Python, Guido van Rossum: Dieser bemühte sich über Jahre, Frauen zu ermutigen, sich als Core-Entwicklerinnen zu beteiligen. Auch er zog sich jetzt zurück, jedoch um nachfolgenden Generationen Platz zu machen.
So unterhaltsam die anarchischen Tiraden eines Linus Torvalds (das öffentliche „Fuck You“ in Richtung NVIDIA) zuweilen sein konnten, so kontraproduktiv ist letztlich der Mangel an Professionalität.
Und nicht zuletzt sollten wir besser an der Stärkung und Weiterentwicklung demokratischer Strukturen arbeiten, anstatt uns an autoritären Diktaturen zu orientieren, seien sie auch noch so wohlgesonnen.
 Sebastian Meyen | Chefredakteur
Sebastian Meyen | Chefredakteur




Die EU-DSGVO entfaltet seit dem 28. Mai ihre Wucht durch Wirksamkeit. Nahezu alle Unternehmen und Organisationen sind gefordert, personenbezogene Daten zu schützen, besonders zu behandeln und Datenflut zu vermeiden. Einige Unternehmen wie die SCHUFA sehen ihre Geschäftsgrundlage bedroht oder betrachten die Verordnung als bürokratischen Overkill, einige private Blogger haben ihre Seiten zumindest vorübergehend vom Netz genommen. Aber ist das denn schon alles, was aktuell die IT-Branche bewegt?
Das Telemediengesetz (TMG), das Telekommunikationsgesetz (TKG), das UWG (Bundesgesetz gegen den unlauteren Wettbewerb) und weitere Vorgaben entfalten ihre Wirkung parallel zur EU-DSGVO und halten damit IT-Abteilungen auf Trab. Wenn die EU-Kommission gegen Google im Rahmen eines Kartellverfahrens eine Rekordstrafe in Höhe von 4,3 Milliarden Euro verhängt, zeigt das natürlich mediale Wirkung und befeuert Debatten [1].
Währenddessen legen Managementebenen weiterhin den Fokus auf die Hochverfügbarkeit ihrer IT-Systeme, während Maßnahmen zu IT-Security und IT-Compliance selten auf den Plan treten. Diese Einseitigkeit wird besonders in den sozialen Medien immer deutlicher: Das Datenanalyseunternehmen Cambridge Analytica (CA) ist unerlaubterweise an die persönlichen Daten von bis zu 87 Millionen Nutzern von Facebook gelangt [2]. Das war nur möglich, weil Facebook primär sein Geschäftsmodell – Handel mit Daten – in den Vordergrund stellte und die Rechte seiner Nutzer fortgesetzt missachtete. Zu guter Letzt hat das soziale Netz daraus auch nichts gelernt, da die erste rechtliche Schutzmaßnahme für Facebook, sein eigener Schutz, Vorrang hatte und veranlasste, dass 1,5 Milliarden Facebook-Konten [3] aus dem EU-Datenschutzraum verschoben wurden, um Ansprüche dieser Facebook-Kunden aus der EU-DSGVO zu verhindern.
Ein anderes Beispiel findet sich bei Yahoo: Das kalifornische Internetunternehmen bestätigte im September 2016, dass drei Jahre zuvor eine Milliarde Nutzerkonten gehackt wurde. Tatsächlich waren es sogar alle drei Milliarden Konten, wie im Oktober 2017 bekannt wurde.
Wo der Bär tobt
Werfen wir im nächsten Schritt einen Blick auf die Gesamtsituation: In welchen Branchen tobt der Bär mit welchen Gesetzen und Auflagen? EU-DSGVO, TMG, TKG und UWG wirken immer, deshalb braucht es hier keine gesonderte Aufzählung.
Banken: BaFin, IT-SiG (IT-Sicherheitsgesetz) [4]; SOX (Sarbanes-Oxley Act of 2002, USA) [5]. Im Juli 2017 wurden bei dem Finanzdienstleister EQUIFAX bis zu 143 Millionen Kundendaten aus den USA, Großbritannien und Kanada entwendet. Dabei fielen personenbezogene Daten wie die Sozialversicherungsnummern, Führerscheinnummern und 290 000 Kreditkartennummern dem Hackerbetrug zum Opfer. Mangelhafte Programmierung machte diesen Hackerangriff möglich. Der amerikanischen Großbank JP Morgan entwendete ein Hacker im Juli 2014 75 Millionen Datensätze. Gemäß der Datenschutzgrundverordnung würde das heute wahrscheinlich eine erhebliche Bußgeldzahlung zur Folge haben.
Ein weiteres Opfer eines Sicherheitsverstoßes ist das PayPal-Tochterunternehmen TIO Networks, ein kanadisches Unternehmen, das ein Netz von mehr als 60 000 Versorgungsunternehmen und Zahlungsautomaten in ganz Nordamerika betreibt [6]. PayPal hatte TIO Networks Juli 2017 für 238 Millionen Dollar in bar erworben. Und was schreibt die BaFin in ihrem Rundschreiben vom November 2017? „Das Institut hat insbesondere das Informationsrisikomanagement, das Informationssicherheitsmanagement, den IT-Betrieb und die Anwendungsentwicklung quantitativ und qualitativ angemessen mit Personal auszustatten.“ Und weiter „[…] hinsichtlich der Maßnahmen zur Erhaltung einer angemessenen qualitativen Personalausstattung werden insbesondere der Stand der Technik sowie die aktuelle und zukünftige Entwicklung der Bedrohungslage berücksichtigt“ [7]. Damit die IT-Kollegen nicht beunruhigt werden, informieren die Compliance-Mitarbeiter sicherheitshalber die Administratoren und Entwickler nicht über die neuen erhöhten Erwartungen im Bereich IT. BaFin-Rundschreiben haben normativen Charakter für die deutsche Finanzwelt. Konsequenz für die Bankmanager: Personalabbau [8], [9].
Versicherungen: BaFin, IT-SiG. Auch hier zieht die BaFin mit ihrem frischen Rundschreiben 10/2018 „Versicherungsaufsichtliche Anforderungen an die IT (VAIT)“ die Daumenschrauben für die IT-Sicherheit an [10].
Gesundheitswesen: MPG, partiell IT-SiG bei Krankenhäusern. Am 25.05.2017 sind die neuen EU-Verordnungen zu Medizinprodukten ((EU) 2017/745) und In-vitro-Diagnostika ((EU) 2017/746) in Kraft getreten. Der Geltungsbeginn der Verordnungen ist, von einzelnen Vorschriften abgesehen, der 26.05.2020 für Medizinprodukte und der 26.05.2022 für In-vitro-Diagnostika. Übergangsregelungen für Medizinprodukte sind in Artikel 120, Inkrafttreten und Geltungsbeginn in Artikel 123 beschrieben. Für In-vitro-Diagnostika gelten die korrespondierenden Artikel 110 und 113. Bis zum Geltungsbeginn gilt das Medizinproduktegesetz (MPG) fort. Die Medical Device Regulation (MDR) besagt, dass in einzelnen Bereichen verlängerte gesetzliche Aufbewahrungsfristen gelten. So gilt etwa nach der Strahlenschutz- beziehungsweise der Röntgenverordnung sowie für Aufzeichnungen nach dem Transfusionsgesetz eine Frist von bis zu dreißig Jahren. Health Insurance Portability and Accountability Act of 1996, USA (HIPAA) heißt ein Gesetz für sichere digitale Kommunikation und Anwendungen im Gesundheitswesen, das im Januar 2017 in Kraft trat und die Themengebiete Medikationsplan, elektronischer Arztbrief, Videosprechstunden, Versichertenstammdatenmanagement (VSDM), elektronische Patientenakte und elektronisches Patientenfach (wirksam ab 01/2019) sowie Notfalldatenspeicherung (01/2018) wirksam abdeckt.
Wie brisant das Thema IT-Sicherheit im Medizinsektor ist, zeigen zwei Beispiele. Anfang August stellten die beiden Hacker Jonathan Butts und Billy Rios auf der Black Hat in Las Vegas Schwachstellen bei beispielsweise Insulinpumpen und Herzschrittmachern der Firma Medtronic vor und thematisieren den Umgang der Firma mit dieser Schwachstelle. Nach achtzehn Monaten, in denen versucht wurde, mit der Firma über das Problem zu kommunizieren, streitet der Hersteller immer noch ab, dass eine Manipulation der Geräte gravierend sei: „At this time we believe that the risk is low and the benefits of the therapy to people with diabetes outweigh the risk of an individual criminal attack“, Amanda McNulty Sheldon (Medtronic Dir. of Public Public Relations).
Im August 2017 wurden 465 000 Herzschrittmacher der Firma Abbott [11] von der amerikanischen Behörde für Lebens- und Arzneimittel (US Food and Drug Administration, FDA) zurückgerufen, da diese aufgrund einer Sicherheitslücke für einen Cyberangriff genutzt werden konnten. Es bestand also unmittelbare Gefahr für Leib und Leben der Patienten. Das ist leider kein Einzelfall: Ein Jahr zuvor waren Insulinspritzen betroffen.
Im Rahmen der Roland-Berger-Studie Krankenhaus 2017 haben zwei Drittel der befragten Krankenhäuser bekundet, bereits Opfer von Cyberangriffen gewesen zu sein [12]. Das ist ein beunruhigendes Ergebnis, doch die Interessenvertretung der Deutschen Krankenhausgesellschaft e. V. (DKG) hat daraus keine Forderungen wie mehr Geld oder Aufschub der E-Health-Gesetzgebung abgeleitet. Die Konsequenzen: Die Krankenhausgesellschaft muss leider vermelden: „Länder bleiben Investitionsmittel weiter schuldig“ – bei verbesserter technischer Ausstattung und Digitalisierung [13]. Man würde meinen, dass die notwendigen Mittel beigestellt werden, wenn der Gesetzgeber das E-Health-Gesetz auf den Weg bringt und Digitalisierung im Gesundheitswesen anstrebt. Diese beispielhafte Aufzählung ließe sich beliebig fortführen.
Kreditkartenabrechnung: Payment Card Industry Data Security Standard, USA (PCI-DSS) ist eine Richtlinie für Cybersecurity für kleine und mittlere Unternehmen [14]. Die Empfehlungen von US-Behörden verfügen über eine Strahlkraft bis nach Europa: NIST: National Institute of Standards and Technology, Recommended Security Controls for Federal Information Systems and Organizations, USA (NIST 800-53) [15], Protecting Controlled Unclassified Information in Nonfederal Information Systems and Organizations, USA (NIST 800-171) [16], Federal Information Processing Standard (FIPS 140-2), Cryptographic Module Validation Program (CMVP) [17], Defense Information Systems Agency, Security Technical Implementation Guides, USA (DISA STIG) [18].
Cloud-Provider: Anforderungskatalog Cloud Computing (C5) [19]. Egal, von welchem Standard, von welchem Gesetz oder welcher Richtlinie aus wir das Phänomen betrachten: Bei IT-Sicherheit und IT-Compliance stehen diese Fachdomänen bei den Entwicklern und Administratoren auf der Tagesordnung. Exemplarisch zeigt Abbildung 1 eine Aufzählung aus dem Katalog „Standard Center for Internet Security (CIS), Version 7“.
 Abb. 1: Standard Center for Internet Security (CIS), Version 7
Abb. 1: Standard Center for Internet Security (CIS), Version 7Die Sache wird bei IT-Compliance und IT-Sicherheit erst brisant, wenn es um die technische Umsetzung und ethische Bewertung geht. Also die Begrenzung und Steuerung von Netzports, Protokollen und Diensten. Die technische Umsetzung benötigt mindestens das Kleeblatt „PPPP“ (Processes, People, Products and Privacy, deutsch: Prozesse, Menschen, Produkte und Datenschutz) was diametral zu den wirtschaftlichen Interessen der Unternehmen steht (Abb. 2).
 Abb. 2: Die technische Umsetzung benötigt mindestens das Kleeblatt PPPP
Abb. 2: Die technische Umsetzung benötigt mindestens das Kleeblatt PPPP24 Stunden wach(sam)
Ein Beispiel aus der Praxis: Ein IT-Leiter stellte mir stolz sein 24/7-PKI (Public-Key-Infrastruktur-)Team vor – bestehend aus einer Person. Er ist sich wohl bis heute nicht bewusst, warum ich ihn bemitleide. Ruhephasen wie Schlaf, Krankheit, Urlaub und auch den Tod schloss er auf Nachfragen vollständig aus und zeigte sich sogar verblüfft, dass er später vier Wochen auf seine Zertifikate warten musste, wo das doch laut PowerPoint ausgeschlossen war. Eine ethische Bewertung benötigt eine bestimmte Werteverankerung und die daraus resultierende Bewusstmachung dessen, was das Beispiel offenbart.
Hier ein paar Aussagen, die das verdeutlichen: „Mir ist es egal, ob meine Daten von der NSA gelesen werden können“ oder purer Fatalismus: „Die können immer unsere Daten lesen, egal, was wir machen.” Derartige Sätze lösen für mich direkt einige Fragen aus: Wenn es egal ist, warum hänge ich nicht meinen Steuerbescheid und meine Krankheitsgeschichte an das schwarze Brett meiner Wohnanlage? Wenn ich es nicht verhindern kann, warum habe ich an meiner Haustür eine Schließanlage, obwohl doch jeder Schlüsseldienst aufzeigt, dass man in ein paar Minuten in die Anlage einsteigen kann?
Verlassen wir diese Laissez-faire-Sicht, wird schnell klar, dass Unternehmen, insbesondere im Bereich kritischer Infrastrukturen, mit einer Fülle von Verordnungen und Auflagen konfrontiert sind.
Ein Awareness-Problem
Was sind nun die Mindestanforderungen der Standards, Richtlinien und Gesetze an die Firmen? Behörden führen Audits selbst durch oder beauftragen Experten, um sich ein Bild zu machen, inwieweit die gemachten Auskünfte später auch einer Tatsachenprüfung standhalten. Dahinter steckt die Auskunftspflicht. Diese Informationspflicht muss jährlich, bei KRITIS-Institutionen und Unternehmen monatlich, erbracht werden. Die monatlichen Nachweise für KRITIS sollen offenbaren, wo Schwachstellen durch das Patch-Management existieren. Bei Softwareentwicklungen sollten die Testergebnisse gegen OWASP nachgewiesen werden und zu guter Letzt die Abweichungen dokumentiert, die bei den Sicherheitsvorgaben vorliegen, und mit welcher Kritikalität sie eingestuft werden (siehe auch CVSS (Common Vulnerability Scoring System) Scoring [20]), Stand der Technik [21].
Beispielsweise sind Organisationen gemäß BSI-Gesetz (BSIG) § 8a verpflichtet, spätestens zwei Jahre nach Inkrafttreten der Rechtsverordnung „angemessene Vorkehrungen zur Vermeidung von Störungen […] ihrer informationstechnischen Systeme“ nach dem „Stand der Technik“ zu treffen und dies gegenüber dem BSI innerhalb von zwei Jahren (Rechtsverordnung nach § 10 BSIG) unaufgefordert nachzuweisen. Das beinhaltet mindestens Architektur, Prozessbeschreibungen und Penetrationstests. Die betroffenen Unternehmen müssen einen Malwareschutz implementiert haben und betreiben. Gemäß Stand der Technik mindestens bei E-Mail, Internetnutzung und einer Lösung am Arbeitsplatz.
Einer der wesentlichen Angriffspunkte von außen sind die Systemschwachstellen durch nicht gepatchte Systeme. Daher muss mindestens monatlich und in einem Krisenfall innerhalb von vier Stunden gepatcht werden können, was nur mit einem automatisierten Patch-Management-Prozess möglich ist [22].
Information Security Management System (ISMS) [23] dient dazu, Regeln und Methoden vorzuhalten, um die Informationssicherheit in einem Unternehmen oder in einer Organisation zu gewährleisten sowie die Abweichungen und deren Risikoeinschätzungen zu dokumentieren. Hier werden also die gesammelten Daten in Bereichen wie Patch-Management bewertet und festgehalten.
Daten, die im Internet übertragen werden (Data in Transit) oder auf Festplatten gemäß HIPAA, PCI-DSS, BaFin (in den Rundschreiben), BSI etc. gespeichert werden (Data at Rest), müssen nach aktuellen Vorgaben verschlüsselt werden. Das bedeutet beispielsweise, bei Nutzung eines Browsers gibt PCI-DSS TLS 1.1 oder TLS 1.2 in einer bestimmten Ausprägung vor. Für bestimmte Szenarien sollten auch Daten im Speicher (Data in Use), hier seien Datenbanken genannt, mit Verschlüsselung arbeiten.
Wer die Themen Patch-Management, Netzsegmentierung und Identity-and-Access-Management (IAM) erfolgreich umsetzt, hat wahrscheinlich schon 99 Prozent seiner Herausforderungen bewältigt.
In diesen Bereichen kann automatisiert ablaufende, im Idealfall modular aufgebaute Sicherheits- und Prüfsoftware für Betriebssysteme und Applikationen IT- und Compliance-Abteilungen bei den technischen Prüfungen maßgeblich unterstützen und entlasten. Auf mögliche Spezifika und Anforderungen an diese Software gehe ich in einem folgenden Beitrag separat ein.
Zusammenfassend lässt sich festhalten, dass wir eine Wertediskussion und ein daraus abgeleitetes Umdenken benötigen, um mehr Aufmerksamkeit auf IT-Sicherheit und -Compliance zu lenken.
 Pierre Gronau ist Gründer der Gronau IT Cloud Computing GmbH. Seit zwanzig Jahren arbeitet er als Senior-IT-Berater mit umfangreicher Projekterfahrung. Zu seinen Kompetenzfeldern gehören Servervirtualisierungen, Cloud-Computing und Automationslösungen sowie Datensicherheit und IT-Datenschutz. Seine Analyse- und Lösungskompetenz dient Branchen von Gesundheitswesen bis Automotive, von Telekommunikation bis Finanzwesen als Orientierung für Unternehmensentwicklung in puncto Digitalisierungsstrategien und IT-Sicherheitskonzepte.
Pierre Gronau ist Gründer der Gronau IT Cloud Computing GmbH. Seit zwanzig Jahren arbeitet er als Senior-IT-Berater mit umfangreicher Projekterfahrung. Zu seinen Kompetenzfeldern gehören Servervirtualisierungen, Cloud-Computing und Automationslösungen sowie Datensicherheit und IT-Datenschutz. Seine Analyse- und Lösungskompetenz dient Branchen von Gesundheitswesen bis Automotive, von Telekommunikation bis Finanzwesen als Orientierung für Unternehmensentwicklung in puncto Digitalisierungsstrategien und IT-Sicherheitskonzepte.
Links & Literatur
[1] Süddeutsche Zeitung: „Google soll 4,3 Milliarden Euro zahlen“: https://www.sueddeutsche.de/politik/europa-google-soll-milliarden-euro-zahlen-1.4059763
[2] The Guardian: „Revealed: 50 million Facebook profiles harvested for Cambridge Analytica in major data breach“: https://www.theguardian.com/news/2018/mar/17/cambridge-analytica-facebook-influence-us-election
[3] Reuters: „Facebook to put 1.5 billion users out of reach of new EU privacy law“: https://www.reuters.com/article/us-facebook-privacy-eu-exclusive/exclusive-facebook-to-put-1-5-billion-users-out-of-reach-of-new-eu-privacy-law-idUSKBN1HQ00P?il=0
[4] Gesetz zur Erhöhung der Sicherheit informationstechnischer Systeme (IT-Sicherheitsgesetz - ITSiG): https://www.buzer.de/gesetz/11682/index.htm
[5] Wikipedia „SOX“: https://de.wikipedia.org/wiki/Sarbanes-Oxley_Act
[6] PayPal-Pressemitteilung TIO Networks: https://www.documentcloud.org/documents/4320819-PYPL-News-2017-12-01-General-Releases.html
[7] Hessenschau: „Abfindungspraxis irritiert Commerzbank-Mitarbeiter“: https://www.hessenschau.de/wirtschaft/abfindungspraxis-irritiert-commerzbank-mitarbeiter,coba-56plus-100.html
[8] Focus: „Deutsche Bank Stellenabbau soll mehr als 7000 Mitarbeiter treffen“: https://www.focus.de/finanzen/news/deutsche-bank-stellenabbau-soll-mehr-als-7000-mitarbeiter-treffen_id_8978499.html
[9] BaFin-Rundschreiben 10/2017: „Bankaufsichtliche Anforderungen an die IT (BAIT)“: https://www.bafin.de/SharedDocs/Downloads/DE/Rundschreiben/dl_rs_1710_ba_BAIT.html
[10] BaFin-Rundschreiben 10/2018: „Versicherungsaufsichtliche Anforderungen an die IT (VAIT)“: https://www.bafin.de/SharedDocs/Downloads/DE/Rundschreiben/dl_rs_1810_vait_va.html
[11] FDA über Rückholaktion von Abbot: https://www.fda.gov/MedicalDevices/Safety/AlertsandNotices/ucm573669.htm
[12] kma online: „Mittel zur Digitalisierung und IT-Sicherheit in Kliniken fehlen“: https://www.kma-online.de/aktuelles/it-digital-health/detail/mittel-zur-digitalisierung-und-it-sicherheit-in-kliniken-fehlen-a-35214
[13] Pressemitteilung der Deutschen Krankenhausgesellschaft: https://www.dkgev.de/dkg.php/cat/38/aid/39071
[14] VdS-Richtlinie: „Cyber-Security für kleine und mittlere Unternehmen“: http://vds.de/fileadmin/vds_publikationen/vds_3473_web.pdf
[15]NIST 800-53 v4: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-53r4.pdf
[16] NIST 800-171: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-171r1.pdf
[17] Wikipedia Cryptographic Module Validation Program (CMVP): https://en.wikipedia.org/wiki/CMVP
[18] DISA STIG: https://iase.disa.mil/stigs/Pages/index.aspx
[19]BSI-Anforderungskatalogs Cloud Computing: https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/Publikationen/Broschueren/Anforderungskatalog-Cloud_Computing-C5.pdf%3Bjsessionid=25465402A66C5006DF0E75A1D77A1861.2_cid369?__blob=publicationFile&v=3
[20] NIST-Onlinerechner für CVSS (Common Vulnerability Scoring System): https://nvd.nist.gov/vuln-metrics/cvss/v3-calculator
[21] Teletrust Stand der Technik April 2018 – aktualisiert: https://www.teletrust.de/fileadmin/docs/fachgruppen/ag-stand-der-technik/TeleTrusT-Handreichung_Stand_der_Technik_-_Ausgabe_2018.pdf
[22] BSI-Leitfaden für sicheres Patch Management: https://www.bsi-fuer-buerger.de/BSIFB/DE/Empfehlungen/EinrichtungSoftware/UpdatePatchManagement/LeitfadenUpdatemanagement/patchmgment_01.html;jsessionid=77AE33C21351171523F21F61EA44C6A7.1_cid360
[23] BSI-Standard 201: https://www.bsi.bund.de/DE/Themen/ITGrundschutz/ITGrundschutzStandards/Standard201/ITGStandard201_node.html