Java Magazin 3.2016 - It's a Match! Finde die NoSQL-Datenbank, die zu dir passt

Preis: 9,80 €
Erhältlich ab: Februar 2016
Umfang: 100
Autoren / Autorinnen:
George Herczeg ,
Lars Röwekamp ,
Michael Müller ,
Peter Roßbach ,
,
Sebastian Meyen ,
Bernd Fondermann ,
Rakia Ben Sassi ,
Christian Straube ,
Philip StrohStefan Siprell ,
Thorsten Hans ,
Rouven RöhrigMichael Zugelder ,
Ulf Fildebrandt ,
Milad Jason Daivandy ,
Nicolas BärDaniel TakaiChristian Wittwer ,
Eugen Melechow
„To REST or not to REST“, das ist hier die Frage. Eines ist sicher, nur weil ich JSON oder XML Payload via HTTP an einen Server sende oder von eben diesem empfange, habe ich es sicherlich noch nicht zwangsweise mit einem RESTful API zu tun. Was also genau macht eine REST-Schnittstelle aus? Und ab wann kann man sie als wirklich gut gelungen bezeichnen? Spätestens bei dieser Frage gehen die Meinungen stark auseinander.
Bei Diskussionen rund um das Thema REST kommt irgendwann unweigerlich die Frage auf „Ja, ist denn das dann überhaupt noch REST?“. So auch auf dem unlängst in Berlin stattgefundenen Microservices Summit. Die Meinungen, was bei REST erlaubt ist und was nicht, gingen dabei zum Teil weit auseinander. Warum kommt es eigentlich immer wieder zu derartigen Diskussionen rund um den korrekten Einsatz von REST? Und ist dies für das Design eines anwenderfreundlichen API überhaupt von Relevanz?
REST at its best
Wahrscheinlich haben die wenigsten Entwickler von RESTful APIs jemals einen tieferen Blick in die Dissertation von Roy Thomas Fielding [1] aus dem Jahre 2000 geworfen. Fielding beschreibt dort in Kapitel 5 einen neuen Ansatz für netzwerkbasierte Softwarearchitekturen namens REST (Representational State Transfer). Das Interessante daran ist, dass wir in der Dissertation recht wenig über Endpoints, HTTP-Methoden oder gar JSON beziehungsweise XML lesen. Es geht in der Arbeit vielmehr um einen Architekturansatz, der durch Begriffe wie Clientserver, Stateless, Chaching, Uniform Interfaces, Layered System und Code on Demand geprägt ist. Das, was die meisten von uns unter REST verstehen, nämlich die Identifikation einer Ressource durch einen eindeutigen URL sowie dessen Manipulation durch eine Repräsentation der Ressource (JSON oder XML) im Zusammenspiel mit selbsterklärenden Messages (aka HTTP-Methoden), spielt in der Arbeit eher eine untergeordnete Rolle und wird dort mit „the four interface constraints“ bezeichnet. „four?“ wird sich jetzt der eine oder andere aufmerksame Leser fragen. Aber ich lese hier doch nur drei! Richtig. Und genau hier liegt der Knackpunkt. Als viertes Constraint führt Fielding „Hypermedia as the engine of application state“ auf. Die beiden folgenden Zitate von Fielding zeigen, welchen Stellenwert er persönlich den Begriffen Hypermedia und Hypertext im Kontext von REST beimisst:
-
„If the engine of application state (and hence the API) is not driven by hypertext, then it cannot be RESTful and cannot be a REST API. “
-
„A REST API should be entered with no prior knowledge beyond the initial URI. From that point on, all application state transitions must be driven by the client selection of server-provides choices.“
Fielding sagt also, dass ein RESTful API ohne vorherige Kenntnisse jenseits des initialen URI auskommen sollte. Der Aufruf dieses URI liefert eine Liste von Links (als Teil der Payload oder alternativ als Link-Header) mit möglichen und sinnvollen Operationen. Für dieses Modell gibt es natürlich auch ein entsprechendes, mehr oder minder sinnvolles Akronym: HATEOAS (Hypermedia as the Engine of State Transfer).
HATEOAS in Aktion
Zugegeben, das eben geschilderte Szenario klingt für viele wahrscheinlich erst einmal ein wenig abstrakt. Dabei ist es genau das, was uns täglich im Internet begegnet, oder? REST ist also nichts anderes als die Abstraktion des uns bekannten Verhaltens des World Wide Web. Wir rufen einen URI auf und erhalten – neben der einen oder anderen Information – eine Liste von Links, die uns zeigen, welche Operationen genau in diesem Moment möglich beziehungsweise erlaubt sind.
Fragt man zum Beispiel bei einem API einen Ausschnitt einer größeren Datenmenge an, so wären sicherlich neben den reinen Daten im Response zusätzliche Link-Header mit den möglichen Links zum Vor- und Zurücknavigieren innerhalb der Datenmenge sinnvoll. Als Anwender des API müsste ich so im Vorfeld nicht die exakten Link-URIs zum Navigieren kennen, sondern mir nur der Tatsache bewusst sein, dass sich hinter der Referenz der Links previous und next die URIs für das Zurück- und das Vorwärtsblättern befinden. Es gibt mit dem RFC 5988 seit 2010 übrigens sogar einen Standard, der entsprechend Linknamen und deren Semantik festlegt [2]. Also bitte nicht das Rad neu erfinden, sondern wenn möglich und sinnvoll einen der dort aufgeführten Linknamen verwenden.
Bei der Navigation durch eine große Datenmenge ist ja noch vorstellbar, dass das API sinnvolle generische Links für vor, zurück, erste oder letzte Seite liefern kann. Aber wie soll das bei den normalen Ressourcen eines RESTful API funktionieren? Stellen wir uns einmal ein API namens RESTBUCKS vor, mit dem wir Kaffee bestellen und bezahlen können. Das Beispiel stammt übrigens aus dem wirklich guten Buch „REST in Practice“ [3]. Der initiale Aufruf des einzigen uns bekannten URI http://api.restbucks.com/ würde uns eine HTTP-Response mit dem Code 204 (No Content) liefern sowie einen Link-Header mit der Bezeichnung edit und dem URI http://api.restbucks.com/orders. Aufgrund des RFCs wissen wir, dass wir mit diesem URI eine Bestellung aufgeben, verändern oder löschen können. Natürlich ist auch ein Abfragen des Bestellstatus einer ausstehenden Bestellung mit dem Link möglich.
Entscheidend für das Verständnis ist, dass wir natürlich schon vorher wussten, dass man bei RESTBUCKS Kaffeebestellungen aufgeben kann, und auch, dass wir das notwendige JSON-Format kennen. Der dafür zu verwendende URI ist uns aber nicht bekannt und eigentlich auch egal. Geben wir nun mithilfe des zurückgelieferten URI eine Bestellung auf, bekommen wir neben der Bestätigung (Status 204 „No Content“ oder 200 „Ok“ inklusive des Echos der Bestellung, eventuell erweitert um zusätzliche serverseitig angereicherte Informationen) wieder Link-Header zurück, die uns signalisieren, was man nun mit der eben aufgegebenen Bestellung anstellen kann. Diese Link-Header unterscheiden sich – zumindest in Teilen – von den vorherigen, da wir durch unsere Bestellung den State der Anwendung verändert haben.
Ein Link-Header ist typischerweise „self“ mit dem Verweis auf die eben angelegte Ressource. In unserem Fall wäre das zum Beispiel http://api.restbucks.com/orders/123. Mithilfe dieses Links kann man nun jederzeit den Status der Bestellung abfragen. Ein weiterer Link-Header mit der Bezeichnung payment – ebenfalls Bestandteil des RFC 5988 – könnte uns signalisieren, wie wir die offene Bestellung bezahlen können: http://api.restbucks.com/payments/123. Je nach gerade ausgeführter Aktion und dem damit verbundenen serverseitigen Änderungen an dem Application State führen uns die Links also Schritt für Schritt durch die Anwendung oder in unserem Fall durch die möglichen Use Cases des Bestellprozesses.
If it’s not REST, ...
Mal Hand auf Herz, wer von uns geht in all seinen RESTful APIs soweit, wie eben in dem RESTBUCKS-Szenario beschrieben? Ich denke einmal die wenigsten. Aber wie ist nun das eigene API auf der nach oben offenen REST-Richterskala einzuordnen? Darf ich überhaupt noch das Wort REST im Zusammenhang mit meinem API in den Mund nehmen ohne dabei einen Shitstorm aus der Ecke der REST-Puristen zu riskieren?
Als kleinen Lackmustest für die Einordnung des eigenen Web Service lässt sich sehr schön das „Maturity Model“ [4] von Leonard Richardson heranziehen. Richardson klassifiziert in seinem Modell Web Services je nach ihrem Support von URIs, HTTP und Hypermedia in drei unterschiedliche REST-Reifegrade. Eigentlich sind es sogar vier, da es unterhalb der drei legitimen Level noch einen Level 0 gibt, der lediglich XML oder JSON via HTTP-Post über die Leitung schickt und somit eher dem klassischem RPC-Modell entspricht. Dieser Level wird auch gerne mit RESTless bezeichnet, da es mit REST so gut wie keine Gemeinsamkeiten aufweist.
In Level 1 führt Richardson die von REST bekannten Ressourcen und somit unterschiedliche Endpoints pro Ressource ein. In einer Anwendung existieren bei diesem Modell in der Regel mehrere URIs. Allerdings wird weiterhin nur eine HTTP-Methode (meist POST) verwendet und auch sonst auf die erweiterten Möglichkeiten des HTTP-Protokolls verzichtet, wie Header, Return-Codes oder Caching. Level 2 setzt genau da an, wo Level 1 aufhört. Den unterschiedlichen HTTP-Methoden werden Operationen auf den Ressourcen zugeordnet: Abfragen der Ressource via GET, Anlegen via POST oder PUT, Ändern via PUT, partielles Ändern via PATCH und Löschen via DELETE. Und auch die HTTP-Statuscodes werden sinnvoll verwendet, um so zu signalisieren, was auf dem Server mit den Ressourcen passiert ist – oder eben nicht. Erst in Level 3 – aka „the glory of REST“ – führt Richardson Hypermedia und somit ein sich selbsterklärendes System ein.
Fazit
Ok, einigen wir uns also darauf, dass – nach der reinen Lehre – wahrscheinlich die wenigsten von uns bisher den heiligen REST-Olymp erklommen haben. Aber ist das wirklich so schlimm? Wichtig ist doch, dass am Ende ein sprechendes API entsteht, das für den Anwender – also den Entwickler – verständlich ist und eine entsprechende Stabilität mit sich bringt. Vinay Sahni, Gründer von Enchant, schrieb dazu einmal in seinem Blog [5]: „An API is a developer’s UI – just like any UI, it’s important to ensure the user’s experience is thought out carefully!“. Treffender kann man es wohl kaum formulieren.
Aber darf ich meine APIs nun überhaupt RESTful nennen, wenn ich nach Richardson lediglich ein Level unterhalb von 3 erreicht habe? Ich persönlich bin da eher pragmatisch als religiös veranlagt. Wenn mein API die Bedingungen von Level 2 erfüllt, dann würde ich es durchaus als RESTful bezeichnen. Bei Level 1 dagegen eher nicht.
Was aber, wenn ich auf einen bekennenden Level-3-Vertreter treffe, der keine Wahrheit neben der seinen akzeptiert? Oder anders formuliert: Sollte ich in einer solchen Situation auf Teufel komm raus darauf bestehen, ein RESTful API entworfen zu haben. Vielleicht fehlt uns einfach nur ein Terminus für die Formel „RESTful minus HATEOAS“? Wie wäre es mit RESTalike? In diesem Sinne: Stay tuned ...
 Lars Röwekamp ist Geschäftsführer der open knowledge GmbH und berät seit mehr als zehn Jahren Kunden in internationalen Projekten rund um das Thema Enterprise Computing.
Lars Röwekamp ist Geschäftsführer der open knowledge GmbH und berät seit mehr als zehn Jahren Kunden in internationalen Projekten rund um das Thema Enterprise Computing.

Links & Literatur
[1] Fielding, Roy Thomas: „Architectural Styles and the Design of Network-based Software Architectures“, 2000: http://bit.ly/1bgKee2
[2] RFC 5988: http://bit.ly/1S4AZiQ
[3] Webber, Jim et al: „REST in Practice“, O’Reilly, 2010
[4] Richardson Maturity Model: http://bit.ly/1UTV5NC
[5] Vinay Sahnis Blog: http://bit.ly/1kcnQ9w
Das Interessante an Big Data, das als Hype vor einigen Jahren die Bühne des Softwaretheaters betreten hat, ist meiner Meinung nach nicht das „Big“, sondern vor allem das „Data“. Gewiss haben wir es mit immer größeren Datenmengen zu tun, die kontinuierlich erzeugt werden. Es heißt, das weltweite Datenvolumen verdopple sich alle zwei Jahre! Und gewiss wird die Fähigkeit, mit unstrukturierten Daten etwas Sinnvolles anzufangen, immer wichtiger. Mehr noch aber fasziniert mich die Tatsache, dass die Big-Data-Diskussion den Blick der Softwareentwickler auf einen Bereich gerichtet hat, der für sie lange Zeit praktisch tabu war: die Datenhaltung.
Seit Big Data und der einher gehenden Welle innovativer NoSQL-Datenbanken ist die Welt der Datenspeicher für den Entwickler keine Blackbox mehr. Erinnern wir uns: Ein langes Jahrzehnt, das von Java-Enterprise-Technologie und objektrelationalen Mappern à la Hibernate dominiert gewesen ist, bestand die Pflicht des Entwicklers darin, nicht in die Datenbank hineinzuschauen. Datenbanken waren fast ausnahmslos relationale Systeme und sollten so ziemlich alles können – auch wenn nur ein Bruchteil der Funktionalität wirklich gebraucht wurde und selbst, wenn es um Anwendungen ging, die vielleicht ganz andere Features benötigten als das, was Oracle, MySQL, DB2 und Co. mitbringen.
In gewisser Weise passte diese – Gott sei Dank überkommene – One-Size-fits-all-Mentalität gut zur J2EE-Ära, in der die Masse der Entwickler dazu aufgerufen wurde, möglichst wenig selbstständig zu denken und sich stattdessen sklavisch an die gängigen Specs zu halten. Diese Zeit ist jedenfalls vorüber und wir haben uns daran gewöhnt, in komplexen (nicht komplizierten!) Kategorien zu denken und zu handeln. So sind Entwickler heute auch dazu aufgerufen, das Thema Datenspeicherung genauer zu verstehen und vor allem genauer auszuformulieren, worauf es wirklich ankommt. So genannte NoSQL-Datenbanken – deren „No“ im Namen nicht gegen SQL als Abfrage gerichtet ist, sondern lediglich als Absage an die One-Size-fits-All-Datenspeicher verstanden werden sollte – zeichnen sich dadurch aus, dass sie jeweils bestimmte Sachen besonders gut können, andere hingegen nicht. Richtig eingesetzt, können sie erhebliche Vorteile bringen.
Entsprechend ist der Auswahlprozess nicht trivial – weswegen wir in unserem Titelthema einen Einblick geben, wie eine solche Auswahl beispielhaft funktionieren könnte. Die Autoren Stefan Siprell und Philip Stroh geben eine Übersicht über die wesentlichen Merkmale der gängigen alternativen Datenspeicher und helfen, einen systematischen Entscheidungsprozess zu entwickeln.
Eine interessante Lektüre des aktuellen Java Magazins wünscht
 Sebastian Meyen, Chefredakteur
Sebastian Meyen, Chefredakteur



Mit TensorFlow hat Google ein Tool für verteilte Systeme, die Basis der für maschinelles Lernen so wichtigen neuronalen Netze, in die Open-Source-Welt entlassen. Es ist ein weiteres Zeichen, dass maschinelles Lernen den Schritt von den Listen der Technologientrends in die Wirklichkeit macht.
Zwei Disziplinen waren lange Zeit die Außenseiter in ihrer Domäne: In der Informatik die „Künstliche Intelligenz“ (KI), das aufgekratzte Kind mit den Flausen im Kopf, das am Ende nichts zustande brachte. In der Mathematik die Stochastik und Statistik, missverstanden als per Definition ungenaue, mit Restfehlern behaftete und damit minderwertige Betrachtung von Zahlen. In den letzten Jahrzehnten hat in der IT stattdessen der konkrete, hochgenaue, vermeintlich exakte Blick auf die Welt vorgeherrscht. Uns hat interessiert, wie viele Zeilen genau in der Datenbanktabelle sind und exakt wie viele Kunden welches Produkt gekauft haben. Kurz: Es war die Sicht, die eine Bank auf die Welt hat.
Dann trat Amazon auf den Plan und machte sich Machine Learning zunutze, um mir als Kunden neue Dinge zu empfehlen, die andere Kunden mit ähnlichen Warenkörben wie dem meinen bereits gekauft hatten. Und dabei war es nicht entscheidend, dass diese Kunden sich exakt genauso verhalten wie ich, sondern so ähnlich wie möglich, mit einer Toleranz. Machine Learning funktioniert mit Näherungen, mit Häufungen, mit Fehlertoleranzen, also mit Stochastik und Statistik. Mathematisch war man damit zu neuen Ufern aufgebrochen, algorithmisch aber noch nicht. Jede Machine-Learning-Anwendung brauchte seine eigenen Verfahren und Implementierungen und ist damit heute mehr als damals ein recht unübersichtlicher und Know-how-intensiver Bereich der Softwareentwicklung.
Machine Learning löst nicht alle Probleme
Manche Problemstellung lässt sich mit Machine Learning nur mehr schlecht als recht verwirklichen, wie Bilderkennung oder das Verstehen gesprochener Sprache, zumindest nicht soweit, dass man den gewünschten Nutzen daraus zieht. Beispiel Sprache: Die klassischen Verfahren wie HMM (Hidden Markov Models) erlauben das Erkennen von Phonemen, also den Grundlauten, aus denen gesprochene Sprache besteht. Statistische Häufigkeiten von aufeinanderfolgenden Phonemen weisen den Computer auf Silben und Wörter hin. Doch manche ähnlich- oder sogar gleichklingende Wörter sind auf der Lautebene nur schlecht, also mit großer Fehlerhäufigkeit, auseinanderzuhalten. Wir Menschen schaffen das meist, weil wir gleichzeitig auf einer höheren Ebene durch den Wort- und Satzzusammenhang oder den Kontext einer ganzen Unterhaltung Verständnis herstellen und Mehrdeutigkeiten aus der Lautebene auflösen können. Doch für diese Ebenen müssen wiederum andere Machine-Learning-Verfahren zum Einsatz kommen. Es passt alles nicht recht zusammen.
Aus neuronalen Netzen entwickelt sich Deep Learning
An dieser Stelle tritt die KI in Form von neuronalen Netzen (NN) auf den Plan. Neuronale Netze orientieren sich an der – teilweise noch nicht vollständig verstandenen – Funktionsweise des menschlichen Gehirns. Dort sind Unmengen von Knotenpunkten, die Neuronen, mit ihren Nachbarn über Leitungen, den Synapsen, verbunden. Jedes Neuron bekommt über mehrere Synapsen elektrische Eingangssignale, die es zu einem Ausgangssignal verrechnet und an die angeschlossenen Neuronen weiterleitet.
Lange Zeit haben neuronale Netze nicht besser als spezialisierte klassische Verfahren funktioniert. Bei statistischen Verfahren ist die Effektivität höher je mehr Eingangsdaten man hat. Fällt man unter die eine kritische Grenze, funktionieren sie nicht mehr. Neuronale Netze müssen groß sein, um große Eingaben verarbeiten zu können. Doch Rechenressourcen für Statistik und neuronale Netze sind heute billiger denn je jederzeit zu haben. Damit kommen die ehemaligen Außenseiter wieder ins Spiel.
Heutige neuronale Netze haben einen weiteren Vorteil: Sie können in Reihe hintereinandergeschaltet werden und damit verschiedenen Ebenen der Wahrnehmung und des Verstehens abbilden. Beschäftigt sich die erste Ebene eines NNs bei der Bilderkennung mit den einzelnen Pixeln und deren Helligkeit und Farbe, so kann die nächste Ebene die Ausgabe der ersten Ebene zum Erkennen von Linien, Kanten, Flächen oder Kurven verwenden. Mit jedem Schritt wird also die vorherige Information abstrahiert, und aus Linien werden geometrische Gebilde und daraus wiederum Gesichter – im Internet natürlich bevorzugt von Katzen. Für die Anwendung solcher mehrschichtigen neuronalen Netze hat sich der Begriff Deep Learning etabliert.
In einer Unterhaltung stehen aufeinanderfolgende Sätze in einem Zusammenhang. Informationen referenzieren früher Gesagtes und manchmal auch Dinge, die erst später gesagt werden: „Er kam auf mich zu. Er war klein, hieß Felix und bellte laut.“ In diesen beiden Sätzen wird erst am Ende aufgelöst, dass es sich vermutlich um einen Hund handelt. Folglich wandelt sich nachträglich unser Verständnis von „Er kam auf mich zu.“. Das Verstehen von Konversation steht im Mittelpunkt von digitalen Assistenten wie Apples Siri, Cortana von Microsoft oder Google Now. Deep Learning ist die Basis für diese Systeme, die eine recht hohe Abstraktion erreichen müssen.
Deep Learning braucht verteilte Systeme: die Geburt von TensorFlow
Deep Learning funktioniert umso besser, je mehr Daten zum Lernen ins neuronale Netz eingespeist werden. Aus entsprechend vielen künstlichen Neuronen und Synapsen muss dieses Netz dann bestehen. Zu viele, um auf einen einzelnen Rechner zu passen. Es muss also ein verteiltes System her. Open-Source-Projekte wie Theano [1] sind länger etabliert, aber ihnen fehlt die Möglichkeit zur Verteilung. Google hat zu diesem Zweck seit 2011 ein Framework namens DistBelief entwickelt [2].
Der Mehrzwecknachfolger von DistBelief ist nun das Projekt TensorFlow, das von Google im Quelltext auf GitHub veröffentlicht wurde. Es löst Google-intern DistBelief nach und nach ab und wird dort über alle Produktsparten eingesetzt, sei es Search, AdWords, YouTube oder Gmail.
TensorFlow erlaubt es, beliebige neuronale Netze durch gerichtete zyklenfreie Graphen zu repräsentieren. Die Kanten bilden Eingabe und Ausgabe der einzelnen Rechenschritte ab, die Knoten die Verarbeitung aller Eingaben zur Ausgabe. Ein Programm, das auf TensorFlow basiert, muss einen solchen Graphen aufbauen. Dieser ist anwendungsspezifisch und hängt von der Art des Inputs ab. Innerhalb von TensorFlow werden die verarbeiteten Daten als multidimensionale Arrays gespeichert. Solche Gebilde fasst die Mathematik unter dem Begriff „Tensor“ zusammen. Um Input zu erzeugen, lässt sich beispielsweise die gesprochene Sprache über Sampling, also dem Abgreifen von Klangwerten in kurzen Abständen, in einen Eingangsvektor (Tensor 1. Ordnung) überführen, ein Schwarz-Weiß-Bildausschnitt als Pixelmatrix (Tensor 2. Ordnung) oder ein Farbbild als drei solcher Pixelmatrizen, mit den Komponenten Rot, Grün und Blau (Tensor 3. Ordnung). Tensoren sind insbesondere interessant, weil Grafikkarten darauf optimiert sind, sehr schnell unglaublich viele Berechnungen auf ihnen durchführen zu können. Insofern ist es nicht verwunderlich, dass TensorFlow GPU-Computing unterstützt und davon in besonderer Weise profitiert.
Ist der gewünschte Graph aufgebaut, so ist er selbstverständlich keineswegs ohne Weiteres in der Lage, Bilderkennung oder Ähnliches durchzuführen. Auf seine Aufgabe muss er zuerst trainiert werden. Die Trainingsdaten füttert man ihm in Iterationen immer wieder zu und verändert dabei Gewichte innerhalb des Graphen, die den Output so verändern, dass dieser sich dem erwarteten Ausgabewert annähert. Die richtige Strategie bei der Annäherung an den richtigen Output ist einer der wichtigen Durchbrüche der letzten Jahre. Auch hier spielt Stochastik eine wichtige Rolle.
Außerdem nimmt man in regelmäßigen Abständen separate Testdaten her, anhand derer man überprüft, ob das Training des neuronalen Netzes auch für beliebige Inputdaten wirkungsvoll war. Verbessert sich das Ergebnis auf den Testdaten nicht mehr, beendet man das Training. Die Gewichte sind der Zustand des Graphen und werden natürlich – neben seiner Struktur – beibehalten, sobald das neuronale Netz gut funktioniert.
Die besondere Leistung von TensorFlow besteht darin, den Graphen des neuronalen Netzwerks über Rechnergrenzen hinweg abzubilden und darauf effizient zu rechnen. Hier leistet Google Pionierarbeit. Aber die Suchmaschinenfirma aus Kalifornien ist hier nicht alleine. Im universitären Umfeld entstand SINGA [3], das mittlerweile als Inkubatorprojekt bei der Apache Software Foundation gelandet ist [4]. Andere Firmen wie Facebook und Amazon haben eigene Entwicklungen von Deep-Learning-Systemen.
Da die Knoten eines Graphen über ihre Verbindungskanten miteinander kommunizieren, ist es im TensorFlow-Verbund notwendig, ständig über das Netzwerk Information auszutauschen. Diese Problemstellung eines verteilten Systems beherrscht TensorFlow laut Google maßgeschneidert für neuronale Netze. Hauseigene Methoden wie MapReduce und andere haben in diesem Fall nicht so gut funktioniert. Damit rechtfertigt TensorFlow seine Existenz.
Fazit
Deep-Learning-Netzwerke stehen heute noch am Anfang. Sie sind jedoch bereits teilweise in der Lage, ohne Training, also selbsttätig und ohne Aufsicht zu lernen. Es lassen sich beeindruckende und teilweise auch verstörende Ergebnisse erzielen, die über das reine Erkennen hinaus in den Bereich der Erzeugung von neuen Informationen vordringen. Ein Beispiel ist das Hinzufügen oder Entfernen von Brillen aus Gesichtern oder das Generieren von Schlafzimmerbildern [5].
Mit Theano oder TensorFlow (beide Python-basiert) und SINGA (C++) wird Deep Learning immer mehr Programmierern einfach zugänglich und kann in den nächsten Jahren viele Felder des Machine Learnings dominieren. Damit werden KI und Stochastik endgültig ganz oben bei den wichtigen Technologien stehen.
 Bernd Fondermann ist freier Softwareentwickler und hat eine Schwäche für verteilte Systeme und Datenspeicher, die ohne SQL abgefragt werden können. Er ist Member der Apache Software Foundation und versucht, mit der Vielzahl der Incubator-Projekte dort schrittzuhalten.
Bernd Fondermann ist freier Softwareentwickler und hat eine Schwäche für verteilte Systeme und Datenspeicher, die ohne SQL abgefragt werden können. Er ist Member der Apache Software Foundation und versucht, mit der Vielzahl der Incubator-Projekte dort schrittzuhalten.
Links & Literatur
[1] Theano: http://bit.ly/1NpqN0W
[2] Dean, Jeffrey et al.: „Large Scale Distributed Deep Networks“: http://bit.ly/1JbGxRl
[3] Ooi, Beng Chin et al.: „SINGA: A Distributed Deep Learning Platform“: http://bit.ly/1YgDAv9
[4] Apache SINGA: http://bit.ly/1ZbNn2A
[5] Beispiele für Deep Learning auf GitHub: http://bit.ly/1NT362F
AngularJS ist ein tolles Framework, um eine dynamische Webanwendung aufzubauen. Die Einstiegshürde ist niedrig, Ergebnisse sind in kurzer Zeit zu erzielen. Dennoch ist Vorsicht geboten: So schnell eine Anwendung hochgezogen werden kann, so schnell versumpft der Code in überladenen Controllern und komplizierten Abhängigkeiten. Dieser Artikel analysiert häufige Fehler und gibt praktische Empfehlungen, um Projekte so aufzubauen, dass die Wartbarkeit langfristig erhalten bleibt.
Die Definition klingt unspektakulär: AngularJS ist ein JavaScript-Framework für Single-Page-Applikationen. Der dazugehörige Vorteilskatalog liest sich indessen beachtlich: AngularJS unterstützt das bidirektionale Data Binding, ermöglicht „expressive“, also sprechendes HTML, und hilft beim Strukturieren, etwa durch das Model-View-ViewModel-Pattern (MVVM). Außerdem wurde schon beim Entwurf auf gute Testbarkeit geachtet. Es benötigt weder serverseitige Unterstützung noch einen Compilerschritt; also kann man einfach mit einem Texteditor ans Werk gehen. Damit bietet AngularJS einen leichten Einstieg für alle, die mit HTML und JavaScript vertraut sind.
AngularJS ist ein JavaScript-Framework, also stellt sich die Frage, wie AngularJS mit einigen der typischen Herausforderungen in Enterprise-JavaScript-Projekten umgeht. Damit meinen wir beispielsweise den Umstand, dass es keine natürliche Strukturierung der Dateien gibt und der Zusammenhang zwischen den Dateien nur lose ist. Darüber hinaus beziehen wir uns auf die Abwesenheit eines Compilers, die dynamische Typisierung und den Umstand, dass JavaScript kein Klassenkonzept aufweist.
Nun ist JavaScript eine Implementierung des ECMAScript-Standards. Einige der genannten Punkte adressiert bereits dessen sechste Version – ECMAScript 2015, der veraltet auch noch ES6 genannt wird. Zukünftig soll der Standard jährlich aktualisiert werden. Ist damit also alles gut? Im Moment zumindest nicht. Denn der aktuell gängige Standard, also derjenige, den die aktuellen Browser verstehen, ist ES5, nicht ES2015. Wer also von der Möglichkeit Gebrauch macht, TypeScript und ES2015 einzusetzen, kommt häufig nicht umhin, beide in ES5 zu übersetzen. Noch ist ES5 in der Entwicklung viel verbreiteter als TypeScript und ES2015. Solange das gilt, bleiben die genannten Herausforderungen bestehen. Welche Möglichkeiten gibt es also, sie zu meistern?
Modularisierung schützt vor Fehlern
Zunächst zu den beiden ersten Punkten, der fehlenden natürlichen Strukturierung und dem losen Zusammenhang zwischen den Daten: Im Gegensatz zu Java mit seinen festen Konventionen, z. B. für den Zusammenhang zwischen Datei- und Klassennamen, verfügt JavaScript (JS) nicht über Komponenten, Namespaces oder Packages. Entwickler können in JS die Dateinamen individuell festlegen und die Dateien nahezu beliebig füllen, sei es mit Funktionen oder Variablen. Diese Individualität kann es schwer machen, später nachzuvollziehen, welchen Inhalt eine Datei hat und wohin sie gehört. Auch der lose Zusammenhang der Dateien kann schnell zu Fehlermeldungen führen: Da es in JavaScript nicht zwingend erforderlich ist, Abhängigkeiten vorab zu definieren, müssen alle benötigten Dateien im Voraus ausgelesen sein.
Modularisierung kann gegen Fehler aufgrund ungeklärter Abhängigkeiten helfen, allerdings wird sie auch gerne falsch verstanden. Controller stellen in AngularJS Daten und Methoden zur Verfügung und sonst nichts. Laut den AngularJS-FAQ [1] ist beispielsweise ein Controller nicht dazu gedacht, jQuery-Code zu kapseln, der das Document Object Model (DOM) manipuliert. Es gibt einige Diskussionen darüber, ob AngularJS eher ein Model-View-Controller-Pattern oder ein MVVM-Pattern hat. Nach unserer Meinung entspricht Angular einem MVVM-Pattern, legt das Model selbst aber nicht fest. Dieser Umstand begünstigt vermutlich die Tendenz, Controller zu überfrachten. Dessen ungeachtet gehen beide Pattern davon aus, dass die einzelnen Bestandteile weitgehend unabhängig voneinander sein sollten. Unserer Ansicht nach sollte das Model überhaupt nicht vom ViewModel oder der View abhängen. Anders gesagt: Es sollte auch ohne beide funktionieren. Nach unserer Erfahrung lässt sich das Data Binding dann effektiv nutzen, wenn man die Daten an exakt zwei Stellen konvertiert: Beim Laden vom und dann wieder beim Wegschicken an den Server. Damit ergibt sich schematisch folgender Ablauf:
Daten vom Server laden ––> Konvertierung zum ViewModel ––> Data-Binding ––> beim Absenden eine Konvertierung ––> Sendung an den Server
Nicht empfehlenswert ist es dagegen, die Daten vom Server zu laden und zu versuchen, sie direkt an die Oberfläche zu binden, von wo aus sie dann ohne Konvertierung zurück an den Server gehen. Denn dafür sind die Datenformate meist zu unterschiedlich. Anstatt also das Data Bindung effektiv zu nutzen, kämpft man in diesem Fall damit, Datenformate sehr nah an der Oberfläche hin und her zu konvertieren. Das ist kein Gewinn. Die strikte Trennung von Repräsentations- und Businesslogik ist einer der Grundbausteine in AngularJS.
JavaScript-Build-Prozesse automatisieren
Grundsätzlich spricht allein die Vielzahl der typischerweise notwendigen Schritte im Build-Prozess dafür, soweit möglich zu automatisieren. Gemeint sind zum Beispiel die Minifizierung oder Verkleinerung des Sourcecodes oder dessen Obfuskation, also Vernebelung, um Reverse Engineering zu erschweren. Dazu kommen das Zusammenführen der Dateien (Bundling), um die Zahl der benötigten HTTP-Anfragen zu senken, und weitere obligatorische Aufgaben, etwa die Ausführung der Tests, die Verwaltung von externen Abhängigkeiten, die Prüfung der Dateien auf Syntaxfehler oder Fehler des Linters. Hier sei nochmals auf die Abwesenheit eines Compilers hingewiesen, die es besonders wichtig macht, Fehler mittels Linting und automatisierten Tests früh aufzuspüren. Denn sonst tauchen sie erst zur Laufzeit auf.
Obwohl die Automatisierung klare Vorteile bringt – bessere Testbarkeit, höhere Produktivität, Kostenersparnis bei der Fehlerkorrektur – wird sie gerne vertagt, getreu dem Motto „Wir fangen erst einmal an und automatisieren später“. Ohne Automatisierung müssen Entwickler jedoch Abhängigkeiten gegenüber Dritten manuell pflegen. Tests, die schnelles Feedback geben, existieren nicht, genauso wenig wie ein automatisierter Build-Prozess. Obendrein muss der Build-Server ohne Build- und Testergebnis laufen. Generell besteht die Gefahr, dass aus dem „wir automatisieren später“ ein „wir automatisieren gar nicht“ wird. Deshalb lautet die Empfehlung dahingehend, im Build-Prozess Node. js und npm für die Automatisierung und Entwicklungsabhängigkeiten einzusetzen – vom ersten Moment an. npm als Command-Line-Tool sollte der einzige Einstiegspunkt für das Abhängigkeitsmanagement und die Installation, für den Build-Prozess sowie die Unit und die GUI-Tests sein. Bei Bedarf lässt sich der npm-Einsatz mit Grunt oder gulp ergänzen. Allerdings ist npm besser geeignet, die Komplexität zu senken. Denn Aufgaben wie die Ausführung eines Unit oder GUI-Tests kommen mit einem npm-Einzeiler aus, wohingegen Grunt oder gulp mehrere Zeilen JavaScript benötigen. Grunt-Files in diverse Dateien zu teilen, schafft zwar Abhilfe, aber eben für ein Problem, das mit npm gar nicht erst entstanden wäre.
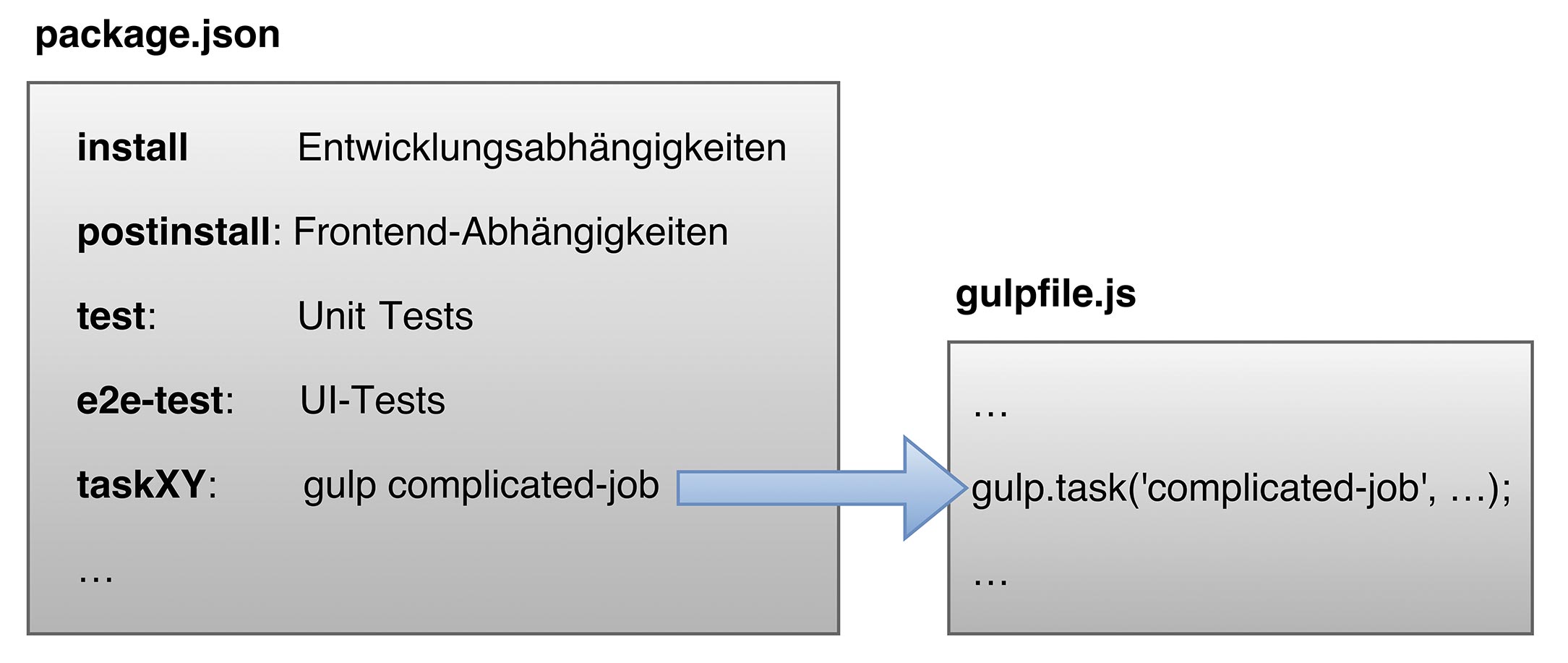 Abb. 1: npm als einziger Einstiegspunkt im Build-Prozess
Abb. 1: npm als einziger Einstiegspunkt im Build-Prozessnpm einzusetzen bedeutet, beliebige JS-Projekte zu standardisieren und autark zu machen. Voraussetzung sind in der Regel lediglich Node.js, Git und die Ausführung der folgenden Schritte:
-
git clone …
-
npm install: Dieser Befehl installiert alle Abhängigkeiten lokal.
-
npm test: Führt Tests aus.
-
npm start: Dieser Schritt ist optional, er startet den Webserver.
In der Folge sinkt die Komplexität massiv, weil diverse umfangreiche Arbeitsschritte stark vereinfacht werden. Beispiel Abhängigkeiten: Sie müssen zwar immer noch definiert werden, das System installiert sie jedoch automatisch und erspart damit manuelles Laden und Einpflegen. Dadurch ergibt sich eine zentrale Stelle, an der alle Versionen definiert werden. Ein Umstand, der nebenbei auch die Update- und Upgrademoral fördert. Die Automatisierung senkt also deutlich das Risiko, viele veraltete Versionen in seinem Projekt zu haben. Nun steht der Begriff Automatisierung normalerweise in Zusammenhang mit den Tests. So auch hier: Wie verhält es sich mit den Unit und GUI-Tests?
Unit Tests sind auch fürs Frontend wichtig
Grundsätzlich begünstigt AngularJS das Testing, beispielsweise aufgrund der strikten Trennung von DOM und JavaScript und über die Dependency Injection, die gerade Unit Tests deutlich vereinfacht. Trotzdem ist die Überzeugung weit verbreitet, wonach Unit Tests für das Frontend eher keine Option sind. Also unterbleiben die Tests, mit der unschönen Folge, dass Fehler erst spät entdeckt werden. Die de facto praktizierte Entwicklung per „Trial and Error“ führt zu Code, der sich weder gut warten noch testen lässt – und damit zu einer langsamen und riskanten Art des Entwickelns. Deswegen gilt: Egal ob Front- oder Backend, Testbarkeit ist eine, wenn nicht die, Metrik für Qualität. Denn solange es möglich ist, gute Tests zu schreiben, ist der Code normalerweise gut isoliert. Übersetzt in AngularJS heißt das, dass sich Controller nur sinnvoll testen lassen, wenn die Logik sauber isoliert wurde. Explizit geht es hier um die strikte Trennung von View und Logik in Controller und Direktiven. Außerdem sei hier erneut die Unabhängigkeit des Controllers vom DOM betont.
Geeignete Werkzeuge für das Unit Testing sind Jasmine oder Mocha als Frameworks. Als Test-Runner empfiehlt sich Karma, das Testausführungen in vielen Browsern erlaubt und über zahlreiche Erweiterungen verfügt. Mit einer davon kann man auch die Codeabdeckung messen und das Ergebnis mittels eines weiteren Plug-ins für CI/Build-Systeme/Server aufbereiten. Der Charme beim Karma-Einsatz ist der hohe Automatisierungsgrad: npm führt Karma aus und Karma führt Jasmine-Tests aus, misst die Codeabdeckung und generiert das Ergebnis.
Häufig möchten Entwickler die Ergebnisse der Unit Tests möglichst schnell haben, um die Feedbackschleife kurz zu halten. Viele Projekte haben einen größeren Build-Prozess, z. B. Minification oder Sass Build. Muss der Code gebaut werden, ehe er getestet wird, ist das akzeptabel für den Build-Server, aber eben schlecht für Test-driven Development und schnelles Feedback. Um trotzdem die Tests schnell ausführen zu können, muss der Build-Prozess gut modularisiert sein und sollte keine unnötigen Aktionen ausführen. Wird z. B. nur eine JavaScript-Datei geändert, sollte etwa der Linter nicht alle JavaScript-Dateien des gesamten Projekts neu analysieren. Dadurch kann das Projekt wachsen, ohne dass der jeweilige Build-Schritt den Entwicklungsprozess zunehmend verlangsamt.
GUI-Tests mit Page Objects
„Spät ist besser als nie“ dürfte auf die Entdeckung von GUI-Fehlern nicht zutreffen. Häufig offenbart die späte Automatisierung schlecht testbares HTML – und zieht dann massiven Aufwand nach sich. Was also stattdessen tun? GUI-Tests ab der ersten Seite, obwohl sie selbst aufwendig sind und schnell veralten? Die Antwort ist ein klares „Jein“. Unserer Erfahrung nach reicht es, sich auf wichtige Use Cases zu konzentrieren und Smoke-Tests zu erstellen: Erste grundlegende Probeläufe einer Software, die simple Probleme offenlegen soll, deren mögliche Auswirkungen allerdings ernst genug sind, um das Programm nochmals zu überarbeiten. Außerdem empfehlen wir zwei grundlegende Dinge: Erstens HTML-Komponenten eine ID zuzuweisen, weil Klassen fehleranfälliger sind. Das ist nicht ganz einfach, da Komponenten wiederverwertbar sein sollten und dennoch eindeutige IDs benötigen. Umso wichtiger ist es, sich darüber von Anfang an Gedanken zu machen. Zweitens Page Objects zu verwenden, egal, ob man mit Protractor, Selenium, Java oder JavaScript arbeitet. Das Page-Objects-Pattern versucht, GUI-Tests wartbarer zu machen, indem Seitenzugriffe – z. B. das Anklicken eines Buttons oder das Ausfüllen eines Felds – in Page Objects gekapselt werden. In diesem programmatischen Ansatz repräsentiert jedes Page Object eine logische Seite. Technisch hat eine Single-Page-Applikation natürlich nur eine Seite, aus Sicht der Nutzer aber quasi mehrere, beispielsweise für das Log-in, Artikeldetails oder Suchergebnisse. Ein Page Object für eine Log-in-Seite besitzt dann Methoden, um die Seiten aufzurufen, den Benutzernamen und das Passwort einzugeben sowie den Log-in-Button zu klicken. Jeder Test, der durch das Log-in muss, verwendet dann das Page Object, um diese Operationen auszuführen. Ändert sich nun die Log-in-Seite, etwa durch einen neuen Log-in-Button, muss nur noch genau ein Test angepasst werden. Eine weitere Empfehlung lautet dahingehend, dass Page Objects ihre benachbarten Page Objects kennen, beispielsweise liefert dann die Log-in-Page das Dashboard Page Object, sobald der Log-in-Vorgang erfolgreich war.
Page Objects repräsentieren eine Webseite in zweierlei Richtung: Dem Entwickler zeigen sie die Dienste oder Funktionalität, die eine spezielle Seite anbietet. Hinsichtlich der Webseite wissen sie, wie sie auf die Elemente zugreifen, idealerweise über deren IDs. Für das Beispiel eines E-Mail-Systems würde das bedeuten, dass die Services umfassen, eine neue Mail zu schreiben, Mails zu lesen oder die Betreffzeilen neuer Mails anzuzeigen. Der Test würde sich also darauf konzentrieren, ob diese Services wunschgemäß funktionieren. Wie sie implementiert werden, ist nicht Gegenstand des Tests. Page Objects kennen auch die Page Objects verlinkter Seiten und wissen, wie man auf die jeweilige Seite zugreift. Damit reduzieren sie die Menge an dupliziertem Code und stellen sicher, dass Änderungen in der Benutzeroberfläche nur an einer Stelle abgebildet werden müssen (Listing 1). Mangelnde (Test-)Automatisierung ist ein großer Fallstrick, allerdings bei Weitem nicht der Einzige. Nachfolgend also vier weitere – und wie sie sich umgehen lassen.
Listing 1
class InboxPage {
constructor() {
this.title = element(by.css("#title"));
this.emails = element.all(by.css("#emaillist li"));
this.newMailButton = element(by.css("#emaillist button.newMail"));
}
open() {
return browser.get("/inbox");
}
writeNewMail() {
return this.newMailButton.click()
.then(() => new WriteMailPage());
}
subjectLine(index) {
return this.emails.get(index).getText();
}
readMail(index) {
return this.emails.get(index).click()
.then(() => new ReadMailPage());
}
}Keine einheitlichen Codekonventionen
Codekonventionen vermindern das Risiko von Flüchtigkeitsfehlern und einfachen Programmierfehlern. Um sie durchzusetzen, empfehlen wir den Einsatz eines Linters. Die statische Codeanalyse überprüft Codekonventionen und findet simple Fehler. Bekannte JavaScript-Linter sind: JSLint (feste Regeln), JSHint (konfigurierbare Regeln, Fork von JSLint) und ESLint (erweiterbare Regeln, Plug-in-basiert). Gute IDEs zeigen die Fehler des Linters direkt im Quellcode an.
IDEs, die JavaScript unzureichend unterstützen
„Wir haben schon immer mit IDE XY entwickelt“ ist ein typischer Satz, der dann problematisch wird, wenn der JavaScript-Support, den XY bietet, schlecht bis nicht existent ist. Konkret bedeutet das, dass beispielsweise keine sinnvolle Autovervollständigung vorhanden ist. Automatisierte Refactorings wie Rename oder Extract Method gibt es auch nicht, genauso wenig wie die Möglichkeit zur Linter-Integration. Zur Deklaration oder Definition von Variablen zu springen erweist sich – vorsichtig ausgedrückt – als schwierige Aufgabe. Genauer gesagt ist es gar nicht möglich, das Problem mittels statischer Analyse zu lösen, solange Definitionen und Deklarationen beliebig sein können. Es liegt eben kein Klassenkonzept vor, die Strukturierung fehlt und der Zusammenhang zwischen den Dateien ist nur lose. Objekte und Methoden können an beliebigen Stellen erzeugt werden. Außerdem können sich Objekte auch strukturell ohne große Hürden ändern, und das zu jeder Zeit. Bei prototypischer Vererbung ist dafür nicht einmal ein Verweis auf das spezifische Objekt erforderlich. Etwa dann, wenn durch das Ändern des Object Prototype plötzlich neue Felder auf allen Objekten auftauchen. Die wenig schönen Folgen der mangelhaften Unterstützung bestehen in der niedrigen Geschwindigkeit der Entwicklung und dem Risiko, vermeidbare Fehler zu machen.
Wir empfehlen daher, eine IDE mit guter JavaScript-Integration zu wählen. Von den kommerziellen Angeboten sind das beispielsweise Visual Studio oder IntelliJ/WebStorm. WebStorm ermöglicht unter anderem automatisiertes Refactoring, die Build-Tool-Integration, die Test-Tool-Integration und die Integration eines Linters. Auch nicht kommerzielle, Plug-in-basierte IDEs bieten eine gute Unterstützung, etwa Brackets, Atom oder Sublime Text. Oft amortisieren sich Aufwand und Kosten des IDE-Wechsels schnell, schon allein aufgrund der signifikant steigenden Entwicklungsgeschwindigkeit.
Schlechte Codequalität
Abstriche an der Codequalität sind dagegen ein schlechter Weg, um die Entwicklung zu beschleunigen. Codeduplikationen sind ein typisches Beispiel für unsauberen Code, sie machen Änderungen aufwendig, weil an vielen Stellen nachgebessert werden muss, bereits gefixte Fehler plötzlich wieder auftauchen oder Features nicht an allen Stellen implementiert sind. In AngularJS-Anwendungen treten Codeduplikationen primär innerhalb von HTML oder in den Controllern auf.
Wie gut sich Unit Tests für Controller schreiben lassen, hängt meist von ihrer Größe ab. Damit Controller nicht überfrachtet werden, bieten sich verschiedene Werkzeuge an. Alle beruhen auf dem Prinzip, wiederverwendbare Teile überhaupt nicht in den Controller zu packen. Die Logik beispielsweise lässt sich in Services auslagern. Allgemein lassen sich die wiederverwendbaren Aspekte der Benutzeroberfläche in Direktiven kapseln, um Coderedundanzen zu vermeiden.
Selbst definierte Direktiven mit sinnvollen Namen sollten grundsätzlich das Mittel der Wahl sein, um AngularJS zu verwenden, anstatt nur einen Controller zu definieren und diesen anschließend über die ng-controller-Direktive zu verwenden. Denn sonst folgen HTML-Duplikationen oder nicht wiederverwendbare Controller. Außerdem drohen komplizierte Scope-Abhängigkeiten und die Gefahr, dass sich ähnliche oder duplizierte Controller einschleichen.
Direktiven sind, wenn sie konsequent angewendet werden, das Feature schlechthin innerhalb von AngularJS. Eine Direktive sollte normalerweise in sich abgeschlossen sein und besteht aus einem HTML-Template, dem Controller, dem Styling und idealerweise einem Satz an Unit Tests. Ihr Hauptkennzeichen besteht darin, dass sie nur ihr eigenes DOM manipuliert.
Mit dem Einsatz der Direktiven mindern Entwickler daher einen der großen Nachteile typischer JavaScript-Anwendungen ab: Gemeint ist, dass jeder Teil einer Anwendung potenziell jeden Teil der Seite beeinflussen kann. Abgeschlossene Direktiven führen dagegen zu Komponenten, die explizite Grenzen haben und damit in großen Anwendungen kombiniert und wiederverwendet werden können. Unser Beispiel illustriert so eine Komponente, es lässt sich über <email-block email="beispielmail"></email-block> verwenden (Listing 2 und 3).
Listing 2: emailBlock.directive.js
class EmailBlockController {
constructor(emailService) {
this.emailService = emailService;
}
get subject() {
return this.email.subject;
}
get text() {
return this.email.text;
}
reply() {
this.emailService.replyTo(this.email);
}
delete() {
this.emailService.delete(this.email);
}
}
angular
.module("beispiel")
.directive("emailBlock", () => ({
scope: {
email: "="
},
controller: EmailBlockController,
controllerAs: "emailBlock",
bindToController: true,
templateUrl: "emailBlock.template.html"
}));Listing 3: emailBlock.template.html
<section>
<header>
<h3>{{emailBlock.subject}}</h3>
<button ng-click="emailBlock.reply()">Reply</button>
<button ng-click="emailBlock.delete()">Delete</button>
</header>
<pre>{{emailBlock.text}}</pre>
</section>Fazit
AngularJS ist nach unserer Erfahrung wirklich ein tolles Framework, wenn man exakt darauf achtet, einige Voraussetzungen zu erfüllen: unter anderem ein hohes Maß an Automatisierung, testbaren Code, Modularisierung und eine strikte Trennung von Repräsentations- und Businesslogik. Damit lassen sich die typischen Herausforderungen der JavaScript-Projekte gut meistern.
Einen interessanten Ausblick bildet der Einsatz von zukünftigen ECMAScript-Features und TypeScript. Die kommenden ECMAScript-Neuerungen ermöglichen es, gängige Probleme einfacher und mit weniger Code zu lösen. TypeScripts Aushängeschild sind das Typsystem und der dazugehörige Compiler. Dieser deckt viele Fehler schon in Sekunden auf, die selbst erfahrene Entwickler sonst oft erst viele Minuten später finden. Mittels Codegenerierung ist es auch möglich, die Kommunikation mit dem Server weitgehend statisch zu verifizieren. Wird etwa auf dem Server ein Attributname geändert, listet der Compiler dann direkt die auf dem Client zu ändernden Stellen auf. Noch gibt es für den TypeScript-Einsatz allerdings einige Einschränkungen, beispielsweise den Zeitbedarf, den der Compilerschritt in Anspruch nimmt, oder die Tatsache, dass AngularJS in Kombination mit TypeScript teilweise schwierig benutzbar ist. Angular 2 stattdessen wird direkt mit TypeScript entwickelt, was hinsichtlich der genannten Einschränkungen signifikante Verbesserungen verspricht.
 Rouven Röhrig ist als Entwickler bei andrena objects ag tätig. Er hat Expertise in der Frontend- und Backend-Entwicklung. Nach mehreren Projekten mit AngularJS hat er an der Entwicklung des ASE-Kurses für JavaScript mitgewirkt und anschließend bei mehreren Kunden als Trainer und ASE-Coach gearbeitet.
Rouven Röhrig ist als Entwickler bei andrena objects ag tätig. Er hat Expertise in der Frontend- und Backend-Entwicklung. Nach mehreren Projekten mit AngularJS hat er an der Entwicklung des ASE-Kurses für JavaScript mitgewirkt und anschließend bei mehreren Kunden als Trainer und ASE-Coach gearbeitet.
 Michael Zugelder ist Softwareentwickler der andrena objects ag und Technologieenthusiast. Nach einigen Jahren mit Schwerpunkt auf Desktopsoftware ist er heute hauptsächlich als Full-Stack-Webentwickler und gelegentlich als Trainer tätig.
Michael Zugelder ist Softwareentwickler der andrena objects ag und Technologieenthusiast. Nach einigen Jahren mit Schwerpunkt auf Desktopsoftware ist er heute hauptsächlich als Full-Stack-Webentwickler und gelegentlich als Trainer tätig.
Links & Literatur
[1] AngularJS-FAQ: http://bit.ly/1zNtHT6